Stayin Alive with Nokia
Me: What if I told you I was going to implement Google's MapReduce white paper?
You: Erik, that's a gargantuan effort! And why would you do that, when Hadoop already exists?
Me: Now what if I said I could do it in less than 20,000 lines of code?
You: Preposterous!
I'd have thought so too, but Nokia Labs has already done it: Meet the Disco Project. This project implements a mapreduce layer on top of a distributed filesystem, with a nice web admin interface. The package is lean, easy to install, and easy to use. I don't see myself ever launching Hadoop again (outside of work). Nokia did it, indeed they could only have done it, using my two favorite languages: Erlang and Python.
I've been playing with it all weekend. The install is
like butter, basically a git clone, a make,
and then start the service (_one_ service, not Hadoop's five). There
are surprisingly few dependencies. The Erlang side has only Lager for
logging and Mochiweb.
I executed the staple word count and grep examples, but wanted to do more. For a test project, I decided I could run queries on my ledger data. Note that I'm interested right now in testing ease of use, not scalability, and so my setup is single-node. Also, my ledger data is hardly a large data set, but it is more than two complete years of transactions, so there are bound to be some interesting queries.
Here's the interface for working with the filesystem:
gentoo01 deps # ddfs -h
Usage:
ddfs
ddfs attrs tag
ddfs blobs [tag ...]
ddfs cat [url ...]
ddfs chtok tag token
ddfs chunk tag [url ...]
ddfs cp source_tag target_tag
ddfs delattr tag attr
ddfs exists tag
ddfs find [tag ...]
ddfs get tag
ddfs getattr tag attr
ddfs ls [prefix ...]
ddfs push tag [file ...]
ddfs put tag [url ...]
ddfs rm [tag ...]
ddfs setattr tag attr val
ddfs stat [tag ...]
ddfs tag tag [url ...]
ddfs touch [tag ...]
ddfs urls [tag ...]
ddfs xcat [urls ...]
Options:
-h, --help display command help
-s SETTINGS, --settings=SETTINGS
use settings file settings
-v, --verbose print debugging messages
-t TOKEN, --token=TOKEN
authorization token to use for tags
Loading the raw ledger file in directly is just ddfs push
ledger ledger. The first 'ledger' is the tag and the second is
the source filename - ddfs references files by tags, rather than the
traditional hierarchical directory structure. Also, if you're keeping
score against Hadoop, note there is no access control; if you can run
ddfs, then you can alter or destroy its entire contents. Also, the
web interface (dynamic via jQuery) is concerned only with mapreduce,
and so filesystem operations are command-line only.
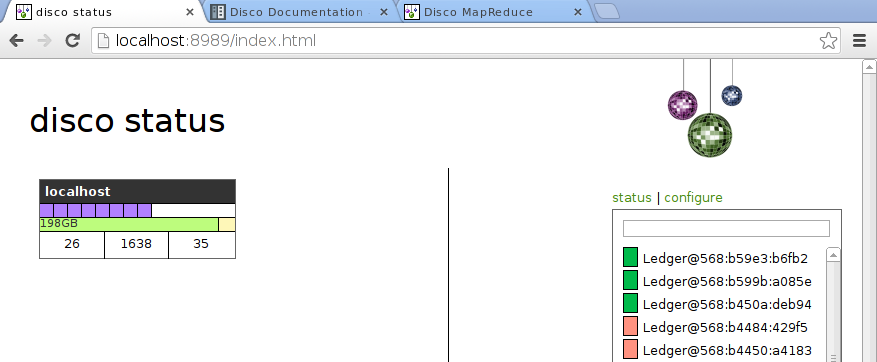
The main cluster status page is fairly spartan. The eight small lavendar boxes are the eight workers I've configured (for an eight-core machine):
Ledger data is stored as multiline entries:
2011/08/04 Dairy Queen Assets:Texans:Checking -22.81 Expenses:Dining/Entertainment 2011/08/04 Northside Market Assets:Texans:Checking -28.39 Expenses:Gas
which I'd first like to denormalize into one-record-per-entry-leg format to make future queries easier:
219bb456-5ef2-54e2-bc92-e0b4f25ff39e ('2011/08/04', 'Dairy Queen', 'Assets:Texans:Checking', -22.81, 'defcur')
219bb456-5ef2-54e2-bc92-e0b4f25ff39e ('2011/08/04', 'Dairy Queen', 'Expenses:Dining/Entertainment', 22.81, 'defcur')
3361d9ef-f865-5e06-adec-13fadbc6072c ('2011/08/04', 'Northside Market', 'Assets:Texans:Checking', -28.39, 'defcur')
3361d9ef-f865-5e06-adec-13fadbc6072c ('2011/08/04', 'Northside Market', 'Expenses:Gas', 28.39, 'defcur')
Already I'm dreading some upcoming pain. The multiline input
format requires special handling of record boundaries, not once but
twice: once during input to the filesystem, and then again when
mapping. For the first problem, Disco provides a ddfs
chunk which can import files to the filesystem in a
content-aware way (I skipped this, knowing my input file is smaller
than the chunk size). Hadoop solves this differently, by ignoring the
issue until the map job starts, then making an extra round-trip to
glue together a record that has been split across nodes (informed by
custom InputFormat and InputSplit classes). This feels reactive and
unnecessarily elaborate.
For the problem of running a 'map' on multiline records, I was pleased at how easy Disco makes this. Here's an abridged snippet from Disco's grep example (jobs are defined with Python):
def map_reader(fd, size, url, params):
for line in fd:
if pattern.match(line):
yield url, line
Note that the map_reader takes in an I/O stream, and I
can read as many lines as I like to yield a map result. Super
easy!
In the end, ledger.py is 110 lines of string processing, a map-only job, to transform raw ledger input to a denormalized flat file as shown above. Most of the code is handling multiple currencies or populating the blank implicit amount value - actual domain problems, not boilerplate. The code is here
Running the job:
gentoo01 jobcode # disco run ledger.Ledger tag://ledger Ledger@568:b59e3:b6fb2
...which results in this status page:
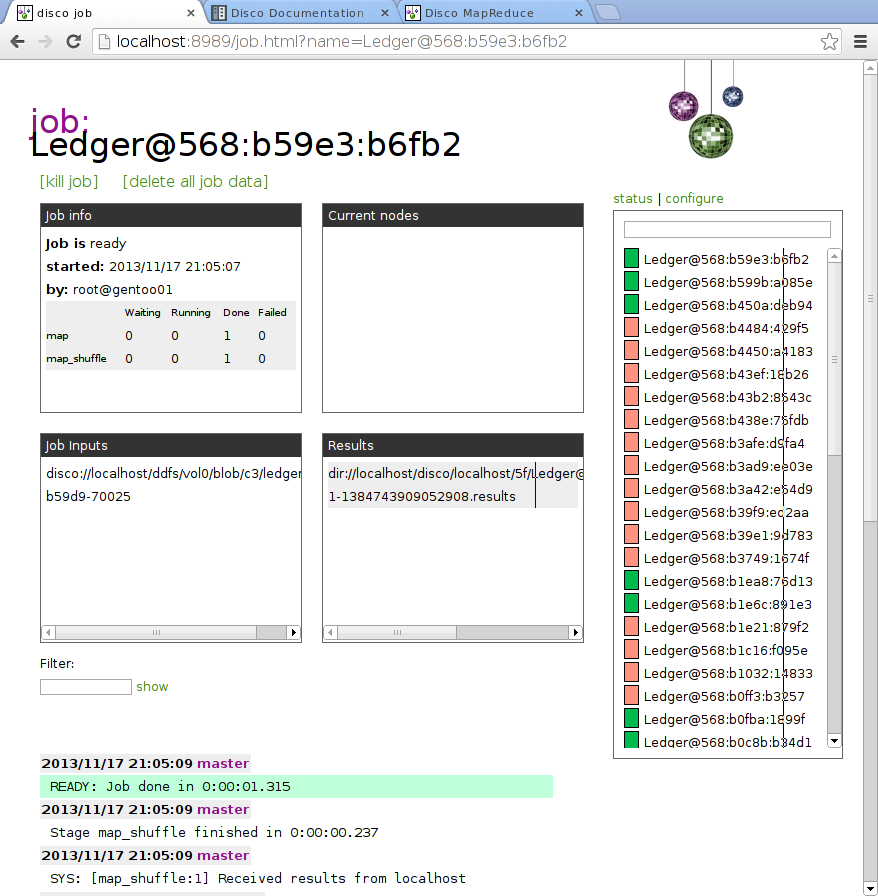
To view the output, which has been stored in ddfs, I xcat the result file into a pager:
gentoo01 jobcode # ddfs xcat dir://localhost/disco/localhost/5f/Ledger@568:b59e3:b6fb2/.disco/map_shuffle-1-1384743909052908.results | less
xcat is the compression-aware version cat command;
ddfs compresses files by default, a feature missing in early Hadoop
versions.
By the way, here is the full command list for administering the mapreduce layer:
gentoo01 jobcode # disco -h
Usage:
disco
disco client_version
disco config
disco debug [host]
disco deref [url ...]
disco events jobname
disco job worker [input ...]
disco jobdict jobname
disco jobs
disco kill jobname ...
disco mapresults jobname
disco master_version
disco nodaemon
disco nodeinfo
disco oob jobname
disco oob get key jobname
disco pstats jobname
disco purge jobname ...
disco restart
disco results jobname
disco run jobclass [input ...]
disco start
disco status
disco stop
disco submit [file]
disco test [testname ...]
disco wait jobname
Options:
-h, --help display command help
-s SETTINGS, --settings=SETTINGS
use settings file settings
-v, --verbose print debugging messages
-t TOKEN, --token=TOKEN
authorization token to use for tags
It's getting late, so I'm going to save further job development for another day. I'm jazzed about it, though, because of how easy I know it will be. Some trivial queries: How much do I spend on dining in a month? How has mortgage principle accelerated downwards? Has my tax withholding corresponded to income?
Consider deploying Disco for your mapreduce needs, assuming your needs include easy to use and elegant.